Использование списков ч.1
Использование списков как множеств
Теория множеств – крайне важная математическая концепция для любых разработчиков. Данные, с которыми работают программы, часто представляются как множества — значит, к ним применимы правила теории множеств. В первую очередь это касается различных операций над множествами, например, пересечения или объединения. Это не значит, что нужно знать эту теорию от и до. Напротив, достаточно изучить ее основные понятия и некоторые операции. Этого хватит для эффективного решения подавляющего числа задач. Сама теория множеств относится к интуитивно понятным концепциям. Она хорошо ложится на здравый смысл и понятна людям даже без особой математической подготовки.
Множеством обозначают набор объектов произвольной природы, который рассматривается как единое целое.
Простейший пример — цифры. Множество всех цифр включает в себя 10 элементов (от 0 до 9).
Но не каждый набор объектов можно назвать множеством.
Существует важное условие – все элементы множества должны быть уникальными.
Например, числа 1, 1 и 3 не могут называться множеством, а 1, 3, 5 могут.
Множества между собой могут находиться в определенных отношениях.
Например, множество натуральных чисел является подмножеством целых чисел, которые в свою очередь являются подмножеством рациональных чисел и так далее.
Понятие «подмножество» означает, что все элементы одного множества также входят в другое множество, называемое надмножеством.
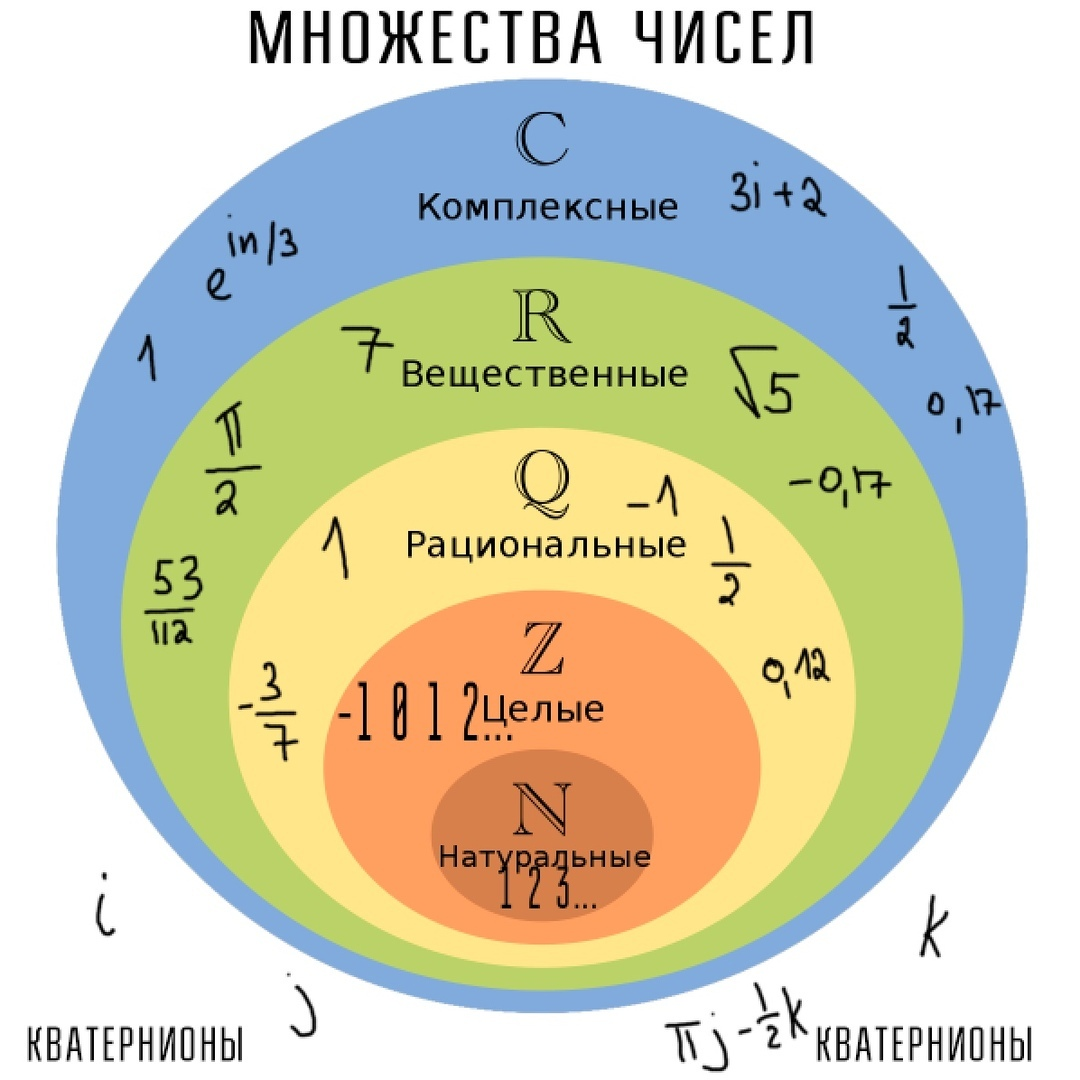 Представление множеств кружками довольно удобно. Можно быстро оценить как друг с другом соотносятся разные множества.
Но математические объекты, такие как числа, не единственные возможные объекты множеств.
Множеством можно назвать группу людей, стоящих на остановке в ожидании своего автобуса, или жильцов квартир одного дома, города или страны.
В программировании в качестве множеств могут выступать списки и таблицы в базе данных.
В Python для представления множеств есть встроенный тип set.
Представление множеств кружками довольно удобно. Можно быстро оценить как друг с другом соотносятся разные множества.
Но математические объекты, такие как числа, не единственные возможные объекты множеств.
Множеством можно назвать группу людей, стоящих на остановке в ожидании своего автобуса, или жильцов квартир одного дома, города или страны.
В программировании в качестве множеств могут выступать списки и таблицы в базе данных.
В Python для представления множеств есть встроенный тип set.
Операции над множествами
На практике представление данных в виде множеств полезно тогда, когда мы хотим что-то сделать с ними. Простой пример. Когда во Вконтакте вы заходите на страницу другого человека, то Вконтакте показывает вам блок с общими друзьями. Если принять, что ваши друзья и друзья вашего друга — два множества, то общие друзья — множество, полученное как пересечение исходных множеств друзей. Пересечение — один из ярких примеров операции над множествами, которая в программировании встречается повсеместно. То же самое можно сказать и о некоторых других операциях. Важно, что результатом всех этих операций являются множества, а значит они подчиняются тем же правилам, что и исходные множества. Например, сохраняется уникальность элементов. В Python нет встроенных методов для работы со списками как с множествами. Поэтому мы используем библиотеку pydash.
Пересечение
Пересечением множеств называется множество, в которое входят элементы, встречающиеся во всех данных множествах одновременно. Пример с общими друзьями:
import pydash.arrays as ar
# Друзья одного человека
friends1 = ['Вася', 'Коля', 'Петя']
# Друзья другого человека
friends2 = ['Игорь', 'Петя', 'Сергей', 'Вася', 'Саша']
# Общие друзья
common_friends = ar.intersection(friends1, friends2)
print(common_friends) # ['Вася', 'Петя']
Объединение
Объединением множеств называется множество, в которое входят элементы всех данных множеств.
import pydash.arrays as ar
friends1 = ['Вася', 'Коля', 'Петя']
friends2 = ['Игорь', 'Петя', 'Сергей', 'Вася', 'Саша']
print(ar.union(friends1, friends2)) # => ['Вася', 'Коля', 'Петя', 'Игорь', 'Сергей', 'Саша']
Каждый друг в объединении встречается ровно один раз.
Разность
Разностью двух множеств называется множество, в которое входят элементы первого множества, не входящие во второе. В программировании такая операция часто называется diff (разница).
import pydash.arrays as ar
friends1 = ['Вася', 'Коля', 'Петя']
friends2 = ['Игорь', 'Петя', 'Сергей', 'Вася', 'Саша']
print(ar.difference(friends1, friends2)) # => ['Коля']
Принадлежность множеству
Проверку принадлежности элемента множеству можно выполнить с помощью встроенного оператора in:
numbers = [4, 13, 21]
print(13 in numbers) # => True
print(5 in numbers) # => False
Управляющие инструкции
В циклах Python доступны для использования две инструкции, влияющие на их поведение: break и continue. Их использование не является необходимым, но все же они встречаются на практике. Поэтому про них нужно знать.
Break
Инструкция break производит выход из цикла. Не из функции, а из цикла. Встретив ее, интерпретатор перестает выполнять текущий цикл и переходит к инструкциям, идущим сразу за циклом.
coll = ['1', '2', '3', '4', 'stop', '6']
for item in coll:
if item == 'stop':
break
print(item)
# => 1
# => 2
# => 3
# => 4
То же самое легко получить без break, используя цикл while. Этот цикл семантически лучше подходит для такой задачи, так как подразумевает неполный перебор:
coll = ['1', '2', '3', '4', 'stop', '6']
i = 0
while coll[i] != 'stop':
print(coll[i])
i += 1
# => 1
# => 2
# => 3
# => 4
Цикл while идеален для ситуаций, когда количество итераций неизвестно заранее. Например, при ожидании условия для выхода или при поиске простого числа — как в коде выше. Если условие в цикле while будет истинным, то цикл будет бесконечным. Важно помнить об этом и всегда проверять условие в таком цикле:
i = 0
# Бесконечный цикл! Опасно запускать!
while True:
print(i)
i += 1
Когда количество итераций известно, предпочтительнее использовать цикл for.
В отличие от while, цикл for in гарантированно остановится после перебора всех элементов, даже если условие break не будет достигнуто:
coll = ['1', '2', '3', '4', '5']
for item in coll:
if False:
# Условие никогда не выполнится, но цикл все равно завершит работу
break
print(item)
# => 1
# => 2
# => 3
# => 4
# => 5
Если же нам нужно совершить полезное действие, если условие в цикле ни разу не выполнилось, то на помощь придет инструкция else:
# Функция возвращает первое число большее, чем переданное, или None, если такого нет
def first_greater(coll, n):
for item in coll:
if item > n:
# Условие никогда не выполнится, но цикл все равно завершит работу
result = item
break
else:
result = None
return result
first_greater([1, 15, 25], 10) # 15
first_greater([1, 15, 25], 42) # None
Continue
Инструкция continue позволяет пропустить итерацию цикла.
Если break дает команду на прерывание, то continue действует более гибко.
Его функция заключается в пропуске определенных элементов последовательности, но без завершения цикла.
Давайте напишем программу, которая «не любит» букву «А»:
word = input('Введите слово: ')
for i in word:
if i == 'а' or i == 'А':
continue
print(i)
Попробуйте ввести, например, «Автобус», в этом случае вывод будет таким:
в
т
о
б
у
с
Pass
Назначение оператора pass — продолжение цикла независимо от наличия внешних условий.
В готовом коде pass встречается нечасто, но полезен в процессе разработки и применяется в качестве «заглушки» там, где код еще не написан.
Например, нам нужно не забыть добавить условие с буквой «а» из примера выше, но сам этот блок по какой-то причине мы пока не написали.
Здесь для корректной работы программы и поможет "заглушка" pass:
word = input('Введите слово: ')
for i in word:
if i == 'а' or i == 'А':
pass
else:
print('Цикл завершен, запрещенных букв не обнаружено')
print('Проверка завершена')
Вложенные списки
Значением списка может быть все что угодно, в том числе другой список. Создать список в списке можно так:
nested1 = [[3]]
print(len(nested1)) # => 1
nested2 = [1, [3, 2], [3, [4]]]
print(len(nested2)) # => 3
Каждый элемент, являющийся списком, рассматривается как единое целое. Это видно по размеру второго списка. Синтаксис Python позволяет размещать элементы создаваемого списка построчно. Перепишем для наглядности создание второго списка:
data2 = [
1, # первый элемент (число)
[3, 2], # второй элемент (список)
[3, [4]], # третий элемент (список)
]
len(data2) # 3
Вложенность никак не ограничивается. Можно создавать список списков со списками внутри и так далее. Обращение ко вложенным спискам выглядит немного необычно, хотя и логично:
data1 = [[3]]
data1[0][0] # 3
data2 = [1, [3, 2], [3, [4]]]
data2[2][1][0] # 4
Возможно, с непривычки вы не всегда сразу точно увидите, как добраться до нужного элемента, но это всего лишь вопрос тренировок:
data2 = [
1,
[3, 2],
[3, [4]],
]
data2[2] # [3, [4]]
data2[2][1] # [4]
data2[2][1][0] # 4
Изменение и добавление списков в список:
data1 = [[3]]
data1[0] = [2, 10]
data1.append([3, 4, 5]) # [[2, 10], [3, 4, 5]]
Вложенные списки можно изменять напрямую, просто обратившись к нужному элементу:
data1 = [[3]]
data1[0][0] = 5 # [[5]]
То же самое касается и добавления нового элемента:
data1 = [[3]]
data1[0].append(10) # [[3, 10]]
Для чего же могут понадобиться вложенные списки? Таких примеров довольно много: начиная от математических концепций, например, матриц, заканчивая представлением игровых полей. Помните игру крестики-нолики? Это как раз тот самый случай. Разберем такую задачку: дано игровое поле для крестиков-ноликов. Нужно написать функцию, которая проверяет, есть ли на этом поле хотя бы один крестик или нолик, в зависимости от того, что попросят проверить.
# Инициализируем поле
field = [
[None, None, None],
[None, None, None],
[None, None, None],
]
# Делаем ход:
field[1][2] = 'x'
# [
# [None, None, None],
# [None, None, 'x'],
# [None, None, None],
# ]
Теперь реализуем функцию, которая выполняет проверку:
def has_player_move(field, symbol):
# Обходим поле. Каждый элемент — это строчка в игровом поле.
for row in field:
# оператор in проверяет присутствует ли элемент в списке,
if symbol in row: # Если присутствует, значит мы нашли то, что искали.
return True
# Если поле было просмотрено, но ничего не нашли,
# значит ходов не было.
return False
Проверим:
print(has_player_move(field, 'x')) # True
Попробуйте сами запустить код в окне ниже с интерпретатором Python и повторите примеры из статьи чтобы самим увидеть и понять как всё это работает. Для этого в ячейке с кодом нажмите клавиши на клавиатуре Shift+Enter или запустите код через кнопку Run по значку ▶.